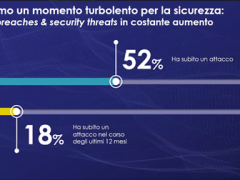
Da quando il cloud è diventato l’infrastruttura di riferimento per tutti, è sempre più frequente scoprire che un disservizio in un punto della rete causa impatti negativi ovunque. Lo scorso 8 giugno, ad esempio, intorno a mezzogiorno, si sono bloccati moltissimi siti tra i più visitati nel mondo: NyTimes, Guardian, BBC, oltre a El Mundo, Financial Times, The Verge, Le Monde, e in Italia, il Corriere della Sera e La Gazzetta dello Sport.
Quando un blocco alla CDN oscura i siti
Non solo giornali online: malfunzionamenti hanno riguardato i servizi di Amazon, Reddit, Twitch e GitHub, ed erano irraggiungibili i siti del governo britannico e della Casa Bianca. I problemi sono durati ore e hanno fatto temere l’ennesimo attacco hacker. In realtà, si è saputo ben presto che il problema era legato a un errore di configurazione della CDN (Content Delivery Network) di Fastly, provider americano di cloud computing (che ha poi individuato e risolto il blocco). Il fatto dimostra però quanto sia oggi centrale la connettività per il funzionamento di molteplici servizi in cloud. Un down causato da problemi di vario genere per un provider “critico” di Internet (e le CDN sono oggi infrastrutture centrali nel garantire la raggiungibilità dei grandi portali della rete) porta a bloccare tutto. Quella che era inizialmente una rete affidabile perché decentralizzata sta diventando sempre più dipendente da alcuni servizi, e quindi in sostanza molto più fragile.
Perdere i dati in un datacenter in cloud
Un arresto simile di molteplici servizi web è stato vissuto anche lo scorso marzo, con l’incidente presso il più grande fornitore di servizi cloud europeo, OVHcloud. Un incendio nella sede di Strasburgo ha distrutto uno dei suoi datacenter e ne ha danneggiato uno vicino. Anche in quel caso il crollo di uno dei punti centrali in cui erano posizionate le risorse di molteplici servizi cloud ha comportato un blocco generalizzato. In aggiunta, l’incendio – a differenza di un problema tecnico – ha distrutto macchine e dati: chi aveva allora misure di ripristino di emergenza o avevano acquistato servizi di backup e ripristino off-site (offerti dalla stessa OVHcloud) ha potuto riavviare le attività e riprendere le operazioni. Chi non si era preparato, invece, ha perso per sempre i propri dati. Anche chi aveva i backup all’interno del sito li ha persi, perché l’incendio si è esteso da un building a quello vicino. Molti clienti poi non avevano predisposto nessun backup, pensando che la sicurezza fosse assicurata dal cloud provider, mentre in realtà, dotarsi di procedure di sicurezza era responsabilità diretta dei clienti.
Gli incidenti continuano ad essere numerosi
Anche il report “Annual Outage Analysis 2021” di Uptime mostra come, nonostante le infrastrutture IT (reti, server, PC e quant’altro) siano diventate sempre più affidabili negli anni, i disservizi (outage) continuano ad essere molto frequenti, a causa anche di un utilizzo sempre più intenso dell’IT.
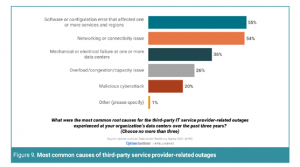
In particolare, dalla ricerca Uptime emerge che negli ultimi 3 anni, almeno 3 persone su 4 (tra responsabili di datacenter e staff IT) hanno osservato un down grave di qualche tipo. Tra le cause degli incidenti gravi in datacenter proprietari, quelle più frequenti sono legate all’alimentazione elettrica del datacenter (37%), seguite da problemi sistemistici per il software (22%) e le reti (17%), per finire con problemi al sistema di raffreddamento (13%). Per quanto riguarda invece l’utilizzo di datacenter di terzi (servizi di hosting e cloud) almeno il 56% delle organizzazioni avrebbero subito un disservizio medio o grave negli ultimi 3 anni. In questo caso, i problemi più frequenti sarebbero di nuovo legati a errori di configurazione software (55%), problemi di connettività (54%), ma un 20% avrebbe indicato anche l’evenienza di un attacco hacker.
Come mettere in piedi un programma di disaster recovery
Questi fatti portano sempre più spesso le aziende a riflettere sull’importanza di prevedere corrette misure di Disaster Recovery e salvataggio dei dati. In un mondo come l’attuale in cui le informazioni sono affidate a cloud provider esterni e i dati critici del business da salvaguardare crescono velocemente in quantità, dotarsi di un piano di continuità operativa che salvaguardi applicazioni, processi e dati, è un aspetto sempre più critico per la stessa sopravvivenza dell’azienda.
Una ricerca che ha indagato l’efficacia delle strategie attuali di Data protection è quella di Unitrends (Data Protection, Cloud, and Proof DRaaS Delivers – Unitrends 2019 Survey Results), che ha presentato alcuni risultati interessanti in termini di utilizzo attuale e prospettico di soluzioni di backup e disaster recovery. In particolare, la ricerca indaga:
- L’attuale efficacia dei programmi di data protection
- L’utilizzo del cloud nell’ambito di una strategia di data protection
- L’efficacia di una soluzione di Disaster Recovery-as-a-Service per un recovery applicativo immediato.
#1 – L’attuale (scarsa) efficacia di programmi di data protection
Dalla ricerca emerge che le aziende continuano a soffrire per livelli elevati di downtime e perdita di dati. Sostanzialmente, un 30% delle organizzazioni ha continuato a perdere dati negli ultimi 5 anni, a causa di malfunzionamenti vari dell’IT. Una percentuale che rimane elevata anche alla luce degli ultimi sviluppi tecnologici, dallo storage in cloud al miglioramento dei backup, al Disaster-Recovery- as-a-Service (DRaaS).
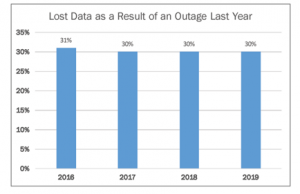
In aggiunta, un downtime nel 2019 è stato vissuto da oltre il 40% dei rispondenti alla survey.
I motivi per cui le aziende continuano a subire downtime sono molteplici:
- una contrazione del budget IT
- una maggiore complessità delle infrastrutture IT (legata alla compresenza di numerosi ambienti, mobile, cloud, SaaS)
- un maggiore ricorso al remote working
- un più elevato volume di dati da proteggere
- un’attività insufficiente di test delle misure predisposte per proteggere e ripristinare i dati.
#2 – Quali volumi di dati sono protetti?
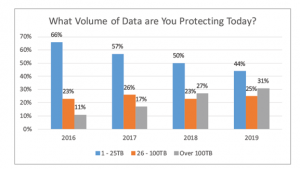
Il volume dei dati che richiedono misure specifiche di protezione è in costante aumento: questo obbliga le aziende a ripensare le proprie strategie di storage e data protection, per ridurre il più possibile i costi associati. La figura successiva mostra che le aziende che avevano necessità di proteggere oltre 100 TB di dati sono passate dall’11% nel 2016 al 31% (quasi 3 volte tanto) nel 2019.
Anche il cloud è oggi un ambiente da considerare nelle strategie di data protection. La maggior parte dei rispondenti ha dichiarato di essere stata obbligata a recuperare parte dei dati posizionati in cloud almeno una volta l’anno. Il 10% ha dovuto farlo più di 5 volte in un anno.
#3 – L’utilizzo del cloud nei programmi di data protection
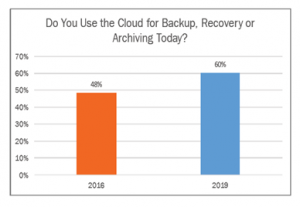
L’utilizzo del cloud a supporto delle attività di protezione dei dati è molto cresciuto negli ultimi anni: il report Uptime ha misurato un 60% di aziende (con una crescita media del +10% tra il 2016 e il 2019) che usano funzioni del cloud per aspetti di storage nel breve periodo, archiviazione, DRaaS, backup diretto da PC e server verso il cloud (particolarmente utilizzato oggi per la forza lavoro mobile). E la percentuale rimane circa uguale considerando aziende di diversa dimensione.
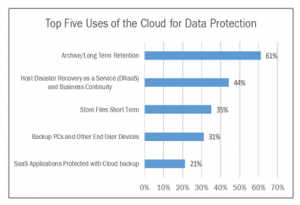
In aggiunta, sta crescendo molto anche il backup in cloud collegato all’utilizzo di servizi SaaS, applicazioni come Office 365, Salesforce, G Suite, che comprendono dati che vanno comunque protetti, così come lo erano quando il software girava su server on premise.
#4 – L’adozione del Disaster Recovery-as-a-Service in cloud
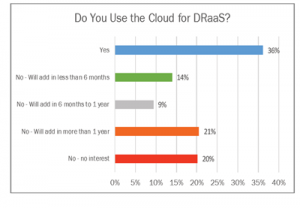
Anche per il Disaster Recovery, la possibilità di dotarsene in modalità SaaS sta trovando sempre maggiore accettazione. Tra chi già se ne è dotato (36% nel 2019) e chi prevede di farlo, si arriva a un 80% delle aziende. Il segnale che l’attenzione sul tema DRaaS è in questo momento molto elevata.
In questo caso, sono soprattutto le grandi organizzazioni ad avere adottato il servizio. Il problema è probabilmente collegato alla mancanza di competenze tecniche necessarie per avvalersi di questi servizi in aziende di minori dimensioni. Il DRaaS non è stato finora soltanto un’assicurazioni in più: ben 4 aziende su 10 hanno dichiarato di averne fatto uso (per disservizi sperimentati sulle proprie infrastrutture), e il 93% di questi ha dichiarato che le performance del DRaaS sono state buone (il restante 7% ha detto che il processo di ripristino è stato troppo lungo o non è avvenuto con un recovery perfetto delle applicazioni).
Via via che i servizi di DRaaS miglioreranno e si adatteranno sempre di più alle esigenze di singole organizzazioni, assisteremo alla possibilità di ottenere ripristini veloci e una riduzione dei downtime (oggi ancora così presenti, come detto in precedenza).
A cura di:
Elena Vaciago, @evaciago
Articoli precedente: IL DISASTER RECOVERY E IL BACKUP MIGRANO AL CLOUD, 3 giugno 2021